监控与警报
中继器在指定的 --metrics 参数的端口上暴露指标。默认端口为 9090,但可以选择任何有效的端口。
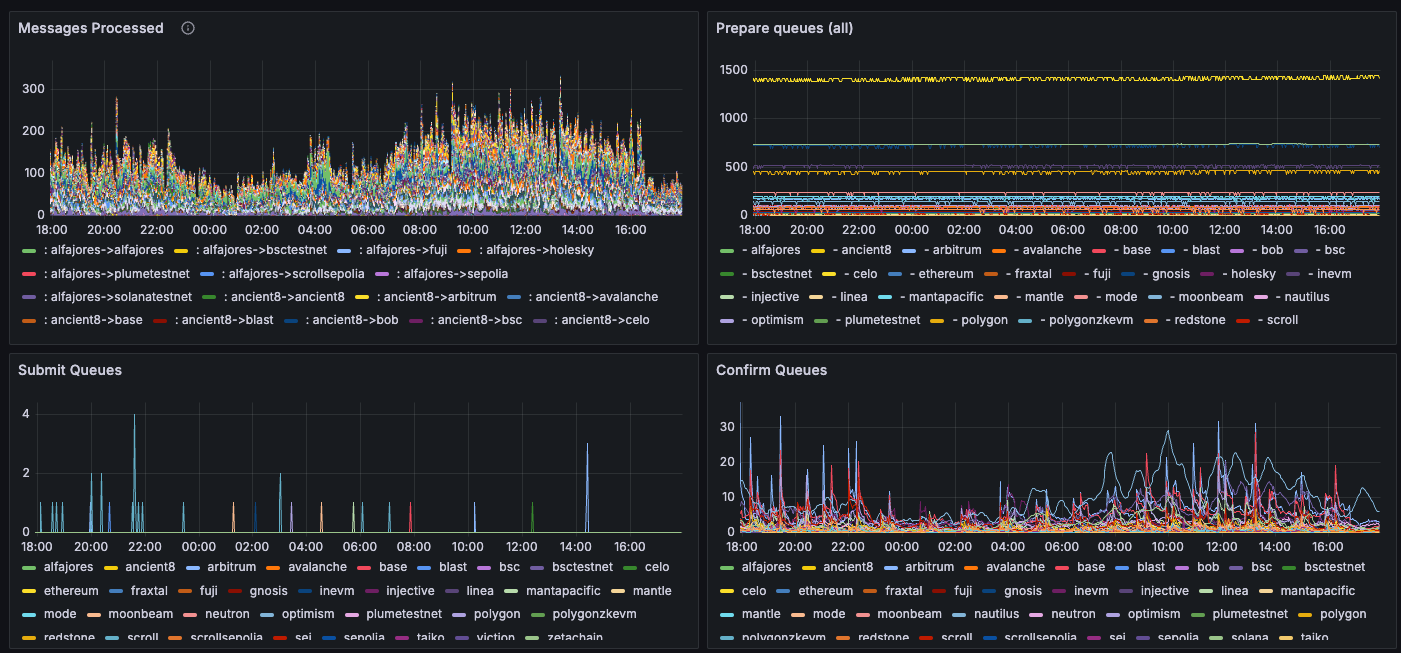
我们建议使用 Prometheus 来抓取这些指标,并使用 Grafana 来可视化它们,使用这个仪表板 JSON 模板,如下所示。这个仪表板的好处在于它可以同时显示多个验证者。截图显示了按链或 Kubernetes Pod 分组的指标。
信息
如果作为 Docker 镜像运行,请确保端口转发指标端点端口。例如,要将本地端口 80 转发到端口 9090,请在 docker run 命令中添加以下标志:-p 9090:80
指标
仪表板模板包括以下指标。
| 指标 | 描述 |
|---|---|
hyperlane_messages_processed_count | 中继器处理的消息数量,按来源和目标链分类("已处理消息")。 |
hyperlane_submitter_queue_length{queue_name="prepare_queue"} | 提交者的准备队列长度("准备队列")。每个目标链都有一个提交者在运行,所有待处理/可重试的消息最终会进入准备队列,等待(重新)提交。该队列的增加可能意味着消息的数量超过了中继器的处理吞吐量,或者提交因各种原因(如坏 RPC、余额不足)而失败。 |
hyperlane_submitter_queue_length{queue_name="submit_queue"} | 提交者的提交队列长度("提交队列")。这些是已经准备好但尚未提交的消息。 |
hyperlane_submitter_queue_length{queue_name="confirm_queue"} | 提交者的确认队列长度("确认队列")。这些是已经提交但尚未确认(最终确定)的消息。 |
其他相关指标包括:
| 指标 | 描述 |
|---|---|
hyperlane_request_count | 记录成功或失败的 RPC 数量,使用以下标签:chain、status(失败或成功)、provider_node(负责的基础 RPC URL)和 RPC method。所有代理都有此指标,但目前仅支持 EVM 链。 |
hyperlane_wallet_balance{agent="relayer"} | 中继器在每个链上的余额,以最低面额单位表示。 |
hyperlane_critical_error | 表示链上关键错误的布尔标记,表示失去活性。 |
hyperlane_block_height | 代理连接的 RPC 节点的区块高度。如果该指标没有增加,则 RPC 可能不健康,需要更换。 |
hyperlane_span_events_total{agent="relayer", event_level="error"} | 记录的错误总数。如果该指标的导数在过去一小时内超过 1,则至少需要发出低严重性警报。请注意,仪表板查询按 Kubernetes Pod 名称分组指标,因此如果您不在 Kubernetes 环境中运行,可能需要调整此查询。 |
hyperlane_span_events_total{agent="relayer", event_level="warn"} | 记录的警告总数。如果该指标的导数在过去一小时内超过 1,则至少需要发出低严重性警报。请注意,仪表板查询按 Kubernetes Pod 名称分组指标,因此如果您不在 Kubernetes 环境中运行,可能需要调整此查询。 |
警报
上述指标可以组合以创建最小化误报的警报。一些示例关键警报:
对于所有代理:
hyperlane_block_height在过去 15 分钟内未增加的任何链- 在过去 10 分钟内,
hyperlane_request_count{status="failure"}的比率 >hyperlane_request_count{status=~"success|failure"}的比率的 60%。大多数代理问题都与坏 RPC 有关,这可能会捕捉到这些问题。
对于中继器:
hyperlane_critical_error为1的链,意味着中继器在该链上失去了活性。虽然其他链的操作不受影响,但这是一个高严重性警报 - 通常与受影响链的不可靠 RPC 有关。- 使用
hyperlane_submitter_queue_length{queue_name="prepare_queue"},准备队列长度在增加,而确认队列长度为零,并且在过去 30 分钟内错误/警告计数差异在增加。这可能意味着中继器余额耗尽,无法支付 gas,或者目标链的 RPC URL 无法正常工作,或者所有新消息都无法处理。 hyperlane_wallet_balance低于某个阈值。例如,当前余额除以过去 24 小时的差值小于 2,意味着余额必须在两天内补充。
如果您收到警报,请始终检查日志以了解可能的问题。